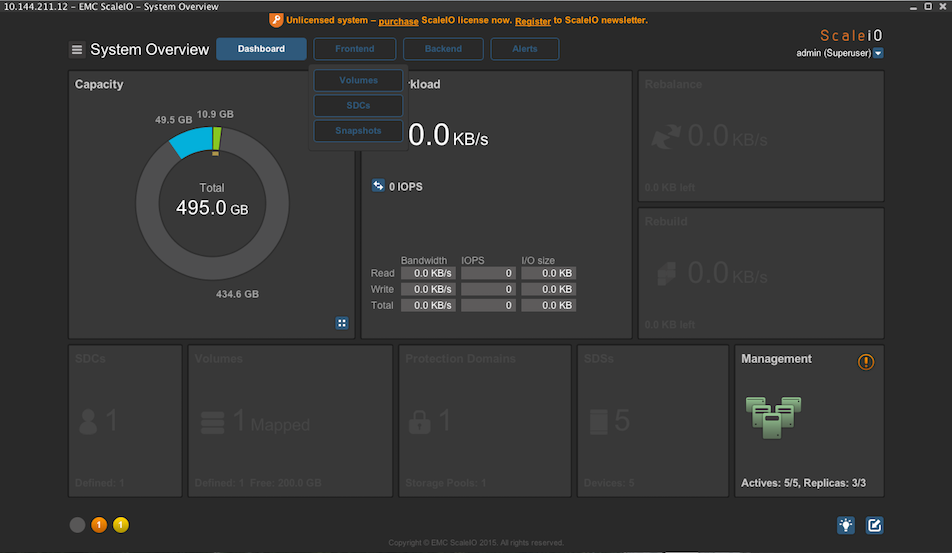
So there is a lot of different constructs within ScaleIO that might make you relate to the picture above. However, do not fear. Lets go through the most critical ones, those that you simply must know in order to configure a system.
ScaleIO Data Server
I touched in this one in a previous post as well, but the SDS is the component from which you map in block devices that can then be pooled and mapped back to the clients.
ScaleIO Data Client
As the name implies, this is the client to which you map volumes to from within ScaleIO.
Meta Data Manager
The most critical component. There can be either 1, 3 or 5 of these depending on the size of the cluster but given that the minimum amount of SDS’s are 3, I see not reason to ever having less that 3. It’s very common to have the first 3 SDS’s also be the MDM’s. These are responsible for knowing where all your storage is at any given time. Loose more than half of these servers and you will be offline. Loose all of them permanently, pray that you didn’t just download free and frictionless and put it into production because you will need to contact support in order to get things back online again. The MDM do take a backup automatically so there should always be a way back from this.
Protection Group
This is the logical grouping of servers that will use each other for parity (provided they have disks in the same storage pool). You can add nodes to a protection group and then create storage pools within the protection group. After that you can add disks to the storage pool or you can introduce an extra layer called a fault domain in which you can add nodes and disks.
A single protection domain can have many storage pools and a storage pool can hold many protection domains and disks. The current maximum for disks in a single storage pool is 300.
Storage Pool
This would then be you group of similar disks. And when I say similar disks, I’m talking about speed. You don’t really have to care about the size of the disks, you have to care about the size of the node in comparison to all the other nodes with disks in that storage pool. Is a perfectly valid use case to have different sizes or nodes, you just have to set the reservation capacity so that its larger than the largest node. I’m I saying that you shouldn’t try to have homogeneous nodes? Absolutely not (personal preference).
It’s also here that you configure the spare percentage, IO priority, ram read cache, checksums and a bunch of other stuff.
Fault Set
Well, you now deployed a system across two racks and now you want to make sure that copy a is in rack a and copy b is in rack b. Well, too bad, you can’t because this has to be setup before putting data on the system. But let’s say that you were planning to do build a new system then this would be the concept you needed to achieve that requirement. Also, this can be used for other things like getting around the maximum size or node (yep, per node… not the physical server).
Order of doing things?
So, let’s put things into order.
- Build the MDM Cluster
- Build the protection domains
- Build the storage pools
- Build the fault sets (optional)
- Add in the SDS
- Add the drives